Exporting and Analyzing Ethereum Blockchain
There are many cases when you want to export Ethereum data to the csv format and run some queries, perform analysis, draw diagrams/charts/graphs etc. Some of the questions you might be interested in:
- When did the first in history ERC20 transfer happen?
- How many ERC20 compatible contracts are there on the blockchain?
- What are the most popular tokens?
- What fraction of ERC20 transfers are sent to new addresses, i.e. addresses that had 0 balance before?
- In what order are transactions included in a block in relation to their gas price?
- What fraction of all transactions are calls to contracts?
- What was the highest transaction throughput?
- What is the total Ether volume?
- Token balance for any address on any date?
- What is the total gas used in all transactions?
- …
In this article I will walk you through the process of exporting Ethereum blocks, transactions and ERC20 transfers using Ethereum ETL, running SQL queries with AWS Athena and visualizing the data in AWS QuickSight.
Read until the end and you will know the answers to the questions above.
Exporting Data to CSV
I exported the first 5 million blocks and the whole process took me:
- 2 EC2-instances with 200 GB SSD disks. Both memory and CPU are important for this task so I chose
t2.medium. You can check other types here https://aws.amazon.com/ec2/instance-types/. As Yann-Aël Le Borgne noted in the comments, usingm5.4xlargecan reduce the total export time to less than 24 hours. - 3 days; $14 (depends on the region). Using Auto Scaling Group can reduce the time to a few hours, read How to Export the Entire Ethereum Blockchain to CSV in 2 hours for $10
Below is the step-by-step guide:
- Create an AWS account if you don’t have one and sign in to the EC2 console https://console.aws.amazon.com/ec2/v2/home
- Launch Ubuntu 16.04
t2.mediuminstance - ssh and install geth following these instructions https://github.com/ethereum/go-ethereum/wiki/Installation-Instructions-for-Ubuntu
- start geth
> nohup geth --cache=1024 &Wait until geth downloads the blocks that you need. You can check it by running:
> geth attach
> eth.syncing
{
currentBlock: 5583296,
highestBlock: 5583377,
knownStates: 65750401,
pulledStates: 65729512,
startingBlock: 5268399
}Normally geth will download the latest state after the blocks are loaded. You don’t need to wait until the full sync though. As soon as geth downloads the blocks you can start exporting the data.
- Clone Ethereum ETL
> git clone https://github.com/medvedev1088/ethereum-etl- Install dependencies
> cd ethereum-etl
> sudo apt-get install python3-pip
> pip3 install -r requirements.txt- Run Ethereum ETL (you may want to comment out the parts that you don’t need in
export_all.shbefore running it):
> nohup bash export_all.sh -s 0 -e 4999999 -b 100000 -p file://$HOME/.ethereum/geth.ipc -o output &Wait until it finishes by inspecting nohup.out. The output will be partitioned in Hive style, every partition containing 100k blocks. Totally 146 files (no ERC20 transfers in first 400k blocks).
Blocks — 4.8 GB:
Transactions — 51.5 GB:
ERC20 transfers — 7.9 GB:
- Sign in to S3 console https://console.aws.amazon.com/s3/home. Create a new bucket and grant appropriate permissions to the EC2 instances.
- Install aws cli https://aws.amazon.com/cli. Configure it by running
> aws configure
AWS Access Key ID:
...You can generate a new access and secret keys in IAM console https://console.aws.amazon.com/iam/home
- Upload the files to S3:
> cd output
> aws s3 sync . s3://<your_bucket>/ethereumetl/exportHere is the price breakdown for Singapore:
- EC2 instances: $0.0584 per hour * ~144 hours = $8.40 https://aws.amazon.com/ec2/pricing/on-demand/. You can save some money if you use Spot instances https://aws.amazon.com/ec2/spot/pricing/.
- EBS storage: $0.12 per GB-month * 400 GB * ~1/10 month = $4.80 https://aws.amazon.com/ebs/pricing/.
- S3 storage: $0.025 per GB-month * 70 GB * ~1/4 month (depends on how long you will keep the files) = $0.44 https://aws.amazon.com/s3/pricing/. You can move the files to Glacier when you don’t use them to save money, which will cost you 5 times less. Alternatively, use Infrequent Access or One Zone-Infrequent Access which will cost you 20–40% less.
You don’t pay data transfer costs into EC2 when synchronizing with the Ethereum network. Data transfers between EC2 and S3 are also free within the same region.
Before you proceed you might want to convert the CSV files into a columnar format: Converting Ethereum ETL files to Parquet. This step is not necessary but it will significantly reduce the running time and the cost of your SQLs.
Running SQLs in AWS Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. You can also connect to it with the JDBC driver.
- Sign in to AWS Athena https://console.aws.amazon.com/athena/home
- Create a database
CREATE DATABASE ethereumetl;- Create tables for blocks, transactions and ERC20 transfers (check up-to-date schema code in this repository https://github.com/medvedev1088/ethereum-etl#querying-in-amazon-athena):
- Run sanity check queries:
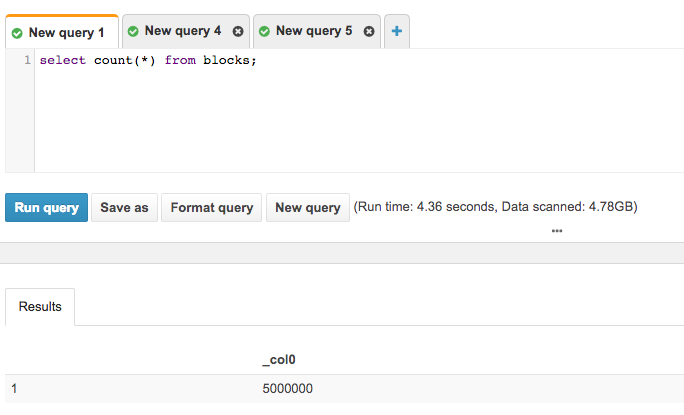



To narrow down the query to partitions that cover a certain block range ($query_start_block, $query_end_block) filter by end_block and start_block — this will reduce the cost and run time:
WHERE ...
AND end_block >= $query_start_block
AND start_block <= $query_end_block;
- Token balance for any address on any block height:
> SELECT token_address, sum(value) AS balance
FROM
(SELECT token_address,
value,
block_number,
to_address AS token_address
FROM token_transfers
UNION
SELECT token_address,
-value,
block_number,
from_address AS token_addres
FROM token_transfers)
WHERE token_address = '0x2cd7e2e65bb6ef5f233f9dea83736cf8195fe70d'
AND block_number < 5600000
GROUP BY token_addresstoken_address balance
0x809826cceab68c387726af962713b64cb5cb3cca 0
0xd3ace836e47f7cf4948dffd8ca2937494c52580c 1500000000000000000000
0xf3e014fe81267870624132ef3a646b8e83853a96 7770000000000000000
0xa4e8c3ec456107ea67d3075bf9e3df3a75823db0 0 0x0947b0e6d821378805c9598291385ce7c791a6b2 0
- The first ERC20 transfer:
> SELECT tx_hash
FROM token_transfers
WHERE start_block < 1000000
ORDER BY block_number limit 10xe2b6c91ffa7e53114df437c2b7ed261672cbfff805aba3dc15bd4d825fdcb6d5
- How many ERC20 compatible contracts are there on the blockchain?
> SELECT count(distinct(token_address))
FROM token_transfers18431
- What fraction of all transactions are calls to contracts? (76%) (This actually should use
receipts.receipt_gas_used)
> SELECT CAST(
(SELECT count(1)
FROM transactions
WHERE gas != 21000) AS DECIMAL(38, 10))/
(SELECT count (1)
FROM transactions)0.7561813736
- What fraction of ERC20 transfers are sent to new addresses, i.e. addresses that had 0 balance before the transfer? (48%)
> SELECT CAST(
(SELECT count(1)
FROM
(SELECT count(1) AS transfer_count
FROM token_transfers
GROUP BY token_address, to_address)) AS DECIMAL(38, 10)) /
(SELECT count(1)
FROM token_transfers)0.4787555243
- What was the highest transaction throughput, assuming 15 seconds block time? (25 transactions per second)
> select max(transaction_count) / 15 from blocks25
- Maximum number of ERC20 transfers per transaction (1000):
> SELECT count(1), tx_hash
FROM token_transfers
GROUP BY tx_hash
ORDER BY 1 DESC limit 11000
0x184d3f0a38b066b8e64a73597b3601e7692f1578d6462a712371b982c31a0a94
- Total Ether volume (5.8 billion Ether ~= $2.9 trillion for $500/Ether):
> select sum(value) from transactions5752307481068270840842025778
- Total value of gas used (746 thousand Ether ~= $373 million ) (this should use
receipts.gas_usedinstead oftransactions.gas):
> select sum(CAST(gas AS DECIMAL(38, 0)) * gas_price) from transactions745703410653020991704491
AWS Athena charges you 5$ per TB of data scanned. You can save on costs and get better performance if compress data, or convert it to columnar formats such as Apache Parquet. Read my article on how to convert the CSVs to Parquet: Converting Ethereum ETL files to Parquet.
Visualizing the Data
Amazon QuickSight is a cloud-powered business analytics service that makes it easy to build visualizations, perform ad-hoc analysis, and get business insights from your data. It allows querying data from Amazon Redshift, Amazon RDS, Amazon Athena, Amazon S3, and Amazon EMR (Presto and Apache Spark); connect to databases like SQL Server, MySQL, and PostgreSQL, in the cloud or on-premises.
- Sign in to QuickSight console https://us-east-1.quicksight.aws.amazon.com/sn/start
- Go to Manage QuickSight on the top right > Account Settings > Edit AWS Permissions. Check the box for Amazon Athena, Amazon S3 and select all S3 buckets
- Return to the QuickSight dashboard and click on Manage Data
- Click on New Data Set and select Athena
- Enter the Data source name and click on Create Data Source
- Select ethereumetl database, then blocks table
- TODO
Here are some visualizations I created:
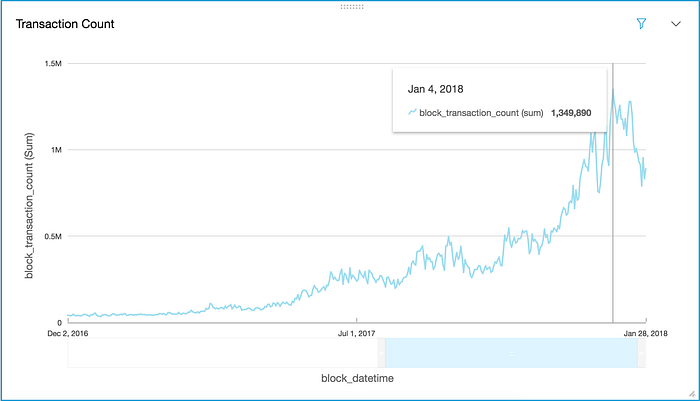
- Transaction Count
- ERC20 Transfer Count
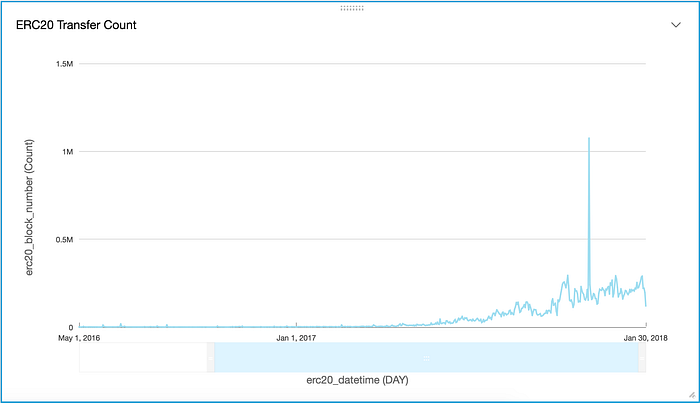
The peak on November 27 with over 1 million transfers is when INS Promo token sale happened https://blog.ins.world/insp-ins-promo-token-mixup-clarified-d67ef20876a3
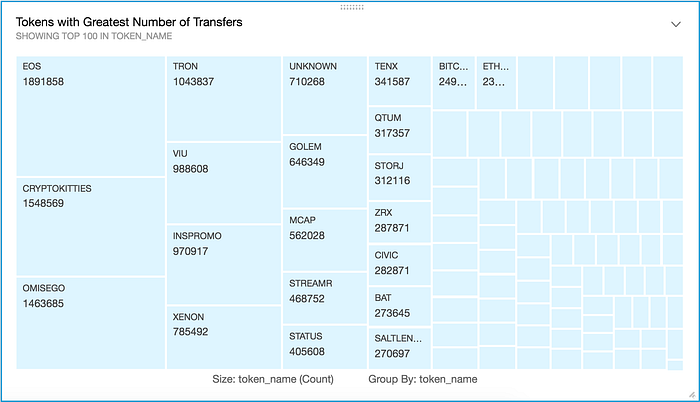
- ERC20 Tokens with Greatest Number of Transfers
AWS QuickSight charges you $12 per user-month, the first user is free https://aws.amazon.com/quicksight/.
Also read:
